
Context Graphs as AI Evaluation Infrastructure
The Governance Layer Enterprise AI Has Been Missing

About the Author: Sandipan Bhaumik have spent almost 2 decades building Data & AI foundations. Now, through AgentBuild Weekly, he shares how builders and founders can move beyond AI hype to create Agentic systems that think, adapt, and truly work.
Enterprise AI evaluation has a measurement problem the field has not yet fully named.
The dominant evaluation paradigm treats model outputs as the primary unit of analysis: given an input, does the system produce an output that is accurate, grounded, and safe? This framing is sufficient for controlled benchmarks. It is insufficient for production AI systems operating inside large organisations, where the context surrounding a model (the data definitions it reasons against, the policies governing its use, the sources it retrieves from) changes continuously, without any corresponding signal in the evaluation pipeline.
This article argues that enterprise AI evaluation fails not primarily because of model limitations, but because evaluation infrastructure is decoupled from the governed context that determines what a correct answer means at a given point in time. We call this context drift. Unlike model drift, which the field has robust tooling to detect and address, context drift has no standard detection mechanism, no common schema, and no established remediation path.
We define context drift precisely, distinguish it from model failure and policy gaps, examine what enterprise context actually consists of and where it lives in the technology stack, and introduce the evaluation graph: a typed, versioned property graph linking evaluation runs to governed context snapshots, including a minimum viable schema for implementation.
The intended audience is data architects, AI/ML engineers, and governance practitioners in regulated enterprises, specifically those who have encountered the moment where a compliance team cannot reproduce an evaluation result. If you have not encountered that moment yet, you will.
A Failure Nobody Has Named
The field has a well-developed vocabulary for model drift. When a model’s behaviour degrades as the world changes around it, we know what to call it, how to detect it, and broadly what to do about it.
There is no equivalent vocabulary for what I will call context drift.
Context drift is what happens when the definitions, policies, data sources, and permissions surrounding an AI system change, and the evaluation infrastructure doesn’t know. The model is the same. The prompt is the same. The output looks the same. But the reality the system is operating against has shifted underneath it, silently, without trace.
Consider what “active customer” means in a financial services context. It is not a stable concept. It has a definition, probably several, owned by different teams, encoded in different systems, disagreed upon in quarterly reviews and quietly revised without announcement. When a credit risk chatbot answers a question about active customers, it is answering against some version of that definition. Which version? As of when? Approved by whom?
If the definition changed three months ago and the evaluation pipeline doesn’t know, the system is being measured against a reality that no longer exists.
That is context drift. Silent, cumulative, invisible to every standard evaluation tool currently in use.

When an enterprise AI system fails, the right diagnostic questions to ask are: was this a model failure, a context failure, or a policy gap?
Those are three different problems. Different owners, different remedies, different implications for compliance. Treating them as one, blaming the model by default, is how teams spend months retraining systems that were never broken.
What Context Actually Is
Prompts and logs show you what was asked and what was answered. They do not show you which version of reality was in force when the answer was generated.
A note before going further: most enterprise data catalogs are not mature enough to serve as evaluation infrastructure without significant preparation. Partial coverage, inconsistently maintained glossary entries, lineage that stops at the ingestion layer rather than following through to serving datasets: this is the reality in most organisations. The framework below describes what each context layer should contain and where it typically lives. In many organisations, the layers exist in incomplete form. Acknowledging that gap up front matters, because propagating incomplete governance into evaluation infrastructure makes the problem harder to see, not easier.
Context, in the enterprise sense, has four layers, and each one has a distinct technical home.
Data context lives in the catalog and lineage layer: which source tables or APIs were consulted, at what point-in-time snapshot, with what certified freshness SLA, owned by which data product team. In a typical catalog and lineage implementation, this is the asset registration layer: table-level lineage, column-level tags, owner metadata, certification status.
Semantic context lives in the business glossary: the precise definition of every business term used in a query or answer, including the version of that definition, its effective date range, which steward approved it, and what exceptions apply. “Net revenue,” “days past due,” “eligible counterparty”: each of these is a versioned artefact, not a static label. In most enterprises they exist in business glossary tools or homegrown systems. What they don’t have is a foreign key into the evaluation log.
Policy context lives in the access control and regulatory layer: which entitlements were active for this user at query time, which data classifications applied to the assets touched, which regulatory regime governed the use case (GDPR, SR 11-7, DORA), and whether any approval workflows were in a specific state. This is the layer that the risk team actually cares about, and it is entirely absent from standard LLMOps tooling.
User context lives in the identity and entitlement layer: who was asking the question, with what role, under what permissions, and in what organisational context. Two users asking the same question against the same definitions may receive different answers because of access controls, regional data residency rules, or role-based filtering. A reproducible evaluation must record not just what the system knew, but who was asking and what they were entitled to see. Without this, the evaluation snapshot is incomplete: you can prove the definitions were stable, but you cannot prove the user’s view of the data was the same.
A standard evaluation log contains none of this. It contains the input, the output, the model version, the latency, and a score. It is a record of what happened. It is not a record of the conditions under which it happened.
That gap is the problem.
Two Worlds That Have Never Met
Governance teams think in assets. AI teams think in runs. One is a noun world. The other is a verb world.
Governance has spent years, in many large financial institutions, more than a decade, building the infrastructure that captures what data means, where it comes from, who owns it, and which rules apply. Lineage graphs. Business glossaries. Data catalogs. Classification tags. Policy registries. This is painstaking, unglamorous work, and in the organisations that have done it seriously, it represents genuine intellectual capital.
AI teams are unaware it exists. Not out of negligence. Out of ontological incompatibility. The governance layer was built to answer the question “what is this asset and what does it mean?” The evaluation pipeline was built to answer “did this run produce a good output?” Those questions have never been asked in the same room, by the same people, against the same underlying record.
At this point, a knowledge graph practitioner will ask the reasonable question: isn’t this just an ontology problem? The answer is: structurally similar, functionally different. An ontology defines what concepts mean across a domain: it is infrastructure for shared meaning. An evaluation graph records what was true, for this system, at this moment, under these conditions: it is infrastructure for defensible evidence. Ontologies govern semantic consistency. Evaluation graphs govern the provenance of a specific result. The evaluation graph consumes ontological inputs; it is not itself an ontology.
A similar distinction applies to context graphs. A context graph captures what data means, who owns it, and what rules apply. It is the living representation of enterprise context. The evaluation graph is not a context graph. It is a consumer of one. It records which version of the context graph was in force for a specific evaluation run. The context graph is the source of truth. The evaluation graph is the audit trail that proves which version of that truth was active when a result was produced.
The reason the wire has never been connected is not technical. The integration is straightforward once both sides agree it matters. The reason is that governance teams measure success in asset coverage and stewardship health scores, while AI teams measure success in model performance and deployment velocity. Neither team has been given a shared reason to converge.
Until something goes wrong in a way that compliance cannot ignore.
Reproducibility Is a Political Problem
The standard argument for better evaluation infrastructure is technical. More coverage. Faster feedback loops. Regression detection. These are real benefits and they matter to engineering teams.
They are not the argument that unlocks the budget in a regulated institution.
The argument that unlocks the budget is this: without a versioned context snapshot attached to every evaluation run, a compliance team cannot legally defend the result.
In any regulated environment (banking, insurance, healthcare, anything touching personal data or consequential decisions) the ability to reproduce an AI result is not a quality metric. It is a regulatory requirement. When an auditor asks “what was the system doing when it produced this output on this date,” the answer cannot be “we ran the same prompt against the same model.” That is not the same context. Definitions changed. Policies updated. A source table was recertified with different ownership. The eval is not reproducible in any meaningful sense.
SR 11-7, the Federal Reserve’s model risk management guidance that most UK banks mirror, requires that models be validated under the conditions in which they operate. The conditions include the data definitions and policy constraints the model reasons against. An evaluation that cannot demonstrate those conditions were stable, or, if unstable, that the instability was tracked, is not a valid model validation.
A definitional snapshot is not a governance nice-to-have. It is the only artefact that makes an eval result legally defensible.
The Chief Risk Officer does not care about evaluation coverage percentages. She cares about whether she can stand in front of a regulator and explain, with evidence, what the system was doing and why. The evaluation graph exists to give her that evidence.
The Evaluation Graph: Schema, Wiring
The argument so far is diagnostic. It is worth diving into the architecture here.
An evaluation graph is a typed, versioned property graph that links an AI evaluation run to the governed context in force at execution time. It is not a replacement for your eval framework, whatever you’re running. It is a context provenance layer that sits alongside it, connected by foreign keys.
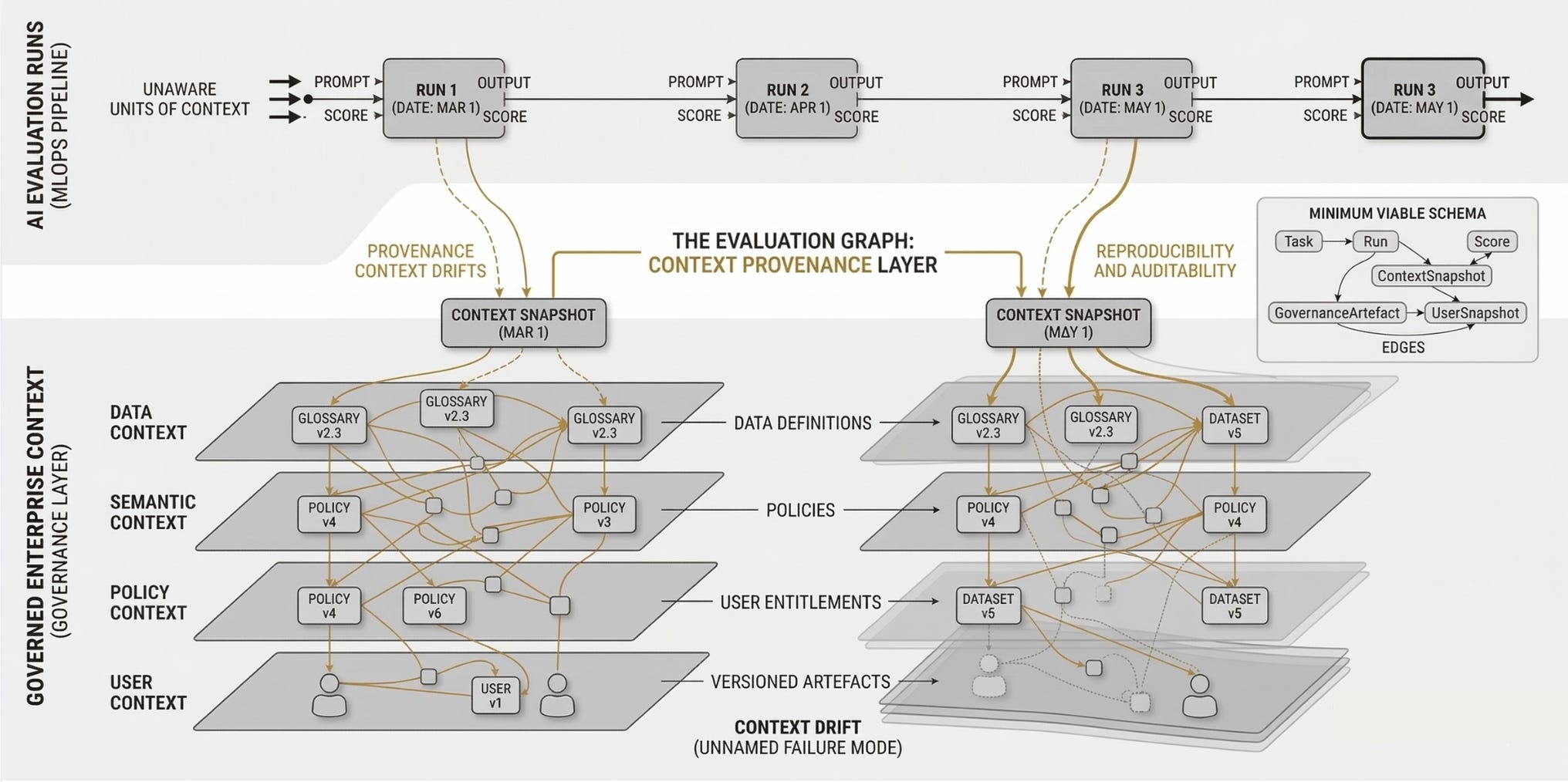
The minimum viable schema has six node types and five primary edge types.
Nodes:
Task: the question, instruction, or scenario presented to the system. Properties: task_id, text, domain, criticality_tier, created_at.
ContextSnapshot: a point-in-time capture of the governed artefacts in force at run time. Properties: snapshot_id, captured_at, snapshot_hash (deterministic hash of all referenced artefact versions, enabling exact reproducibility checks).
Run: the execution record. Properties: run_id, model_version, retrieval_config, tool_manifest, prompt_template_version, execution_timestamp. Foreign key to your existing eval platform’s run record.
Score: evaluation results. Properties: score_id, metric_name, value, evaluator_type (human / LLM-as-judge / deterministic), evaluation_timestamp. One Run can have multiple Score nodes.
GovernanceArtefact: the actual governed asset referenced in the ContextSnapshot. Subtyped as GlossaryTerm, PolicyVersion, DatasetRegistration, or AccessEntitlement. Properties vary by subtype but always include: artefact_id, version, effective_from, effective_to, owner_team, steward_id, source_system.
UserSnapshot: the identity and entitlement state of the user at query time. Properties: user_id, role, active_entitlements, data_residency_region, permission_scope, captured_at. This node ensures that the evaluation record captures not just what the system knew, but who was asking and what they were authorised to see.
Edges:
Run -[USES]-> ContextSnapshot: every run points to exactly one snapshot.
ContextSnapshot -[REFERENCES]-> GovernanceArtefact: a snapshot references one or more versioned artefacts.
Run -[REQUESTED_BY]-> UserSnapshot: every run records the user’s identity and entitlements at execution time.
Task -[EVALUATED_BY]-> Run: a task can have multiple runs (different models, different dates).
Run -[SCORED_AS]-> Score: a run produces one or more scores.
This graph can be stored in any property graph database, or modelled as a set of tables in your lakehouse if you prefer keeping everything in one place. The latter is simpler operationally and sufficient for most enterprise AI evaluation volumes.
Example
A credit risk chatbot at a UK retail bank receives the following question from a relationship manager:
“Is this customer eligible for the bridging facility?”
The evaluation graph for that run records the following:
The Task node captures the question, tagged to the credit_risk domain with criticality_tier high.
The ContextSnapshot node, captured at 09:14:32 on the run date, references three GovernanceArtefacts: the GlossaryTerm “eligible_customer” at version 2.3 (effective since the previous quarter’s model governance review, owned by the Credit Risk Data Office), the PolicyVersion “bridging_facility_eligibility_v4” (active under current FCA product governance framework, approved by the Credit Policy Committee), and the DatasetRegistration for the customer master dataset (certified at gold tier, freshness SLA 24 hours, last recertified 18 hours prior to the run).
The UserSnapshot records that the relationship manager held a “credit_rm” role with entitlements scoped to the retail banking division, with access to customer records in the UK data residency region. A colleague in the investment banking division asking the same question would have a different UserSnapshot, different entitlements, and potentially a different answer, all of which the evaluation graph captures.
The Run node records model version, retrieval configuration pointing to the vector store built against the certified dataset, and the prompt template version.
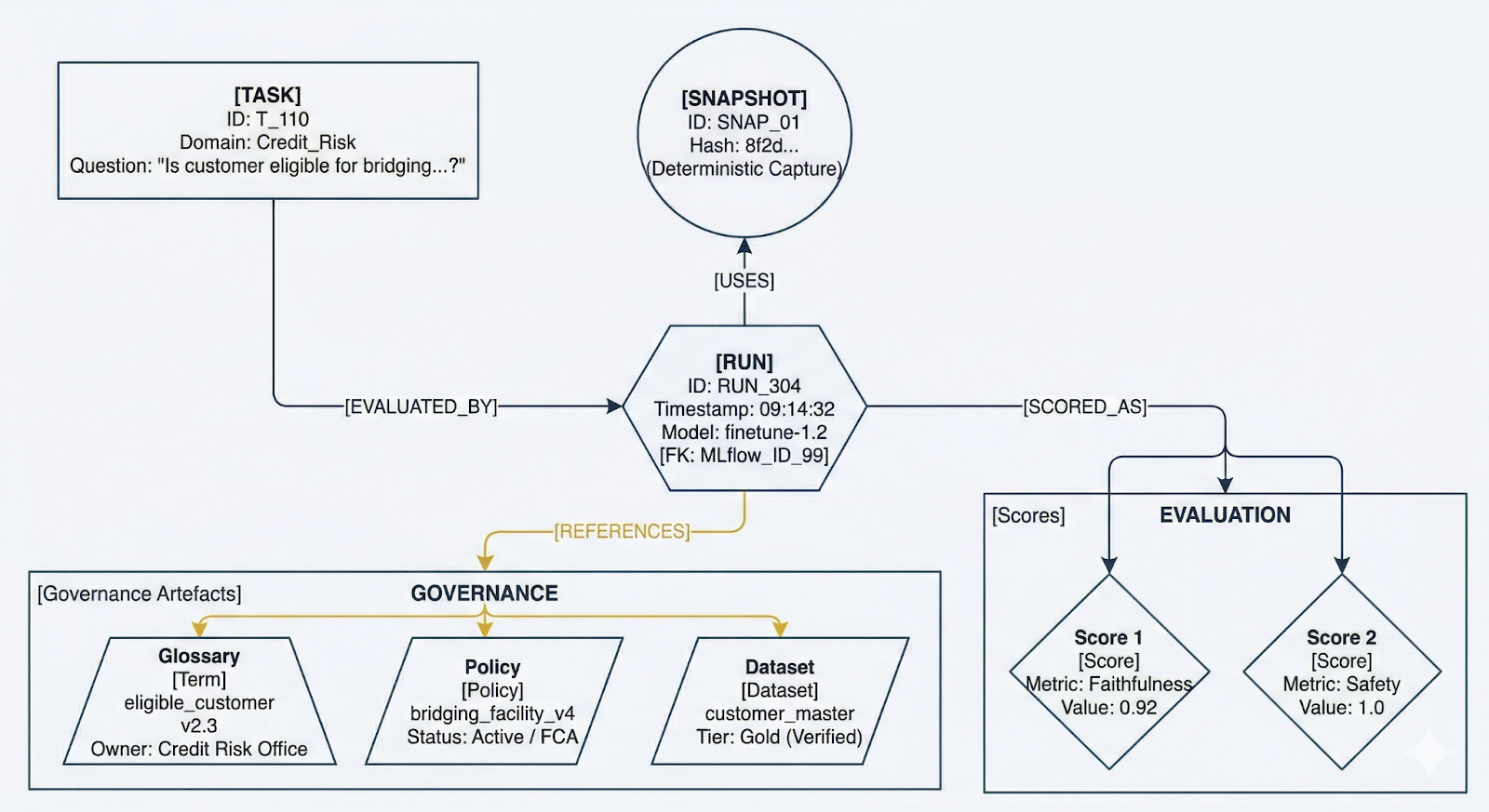
Six months later, when the definition of “eligible_customer” has been revised to version 2.4 and a regulator asks about a decision made in March: the evaluation graph surfaces the exact context. Not an approximation. Not a reconstruction. The deterministic snapshot_hash confirms that version 2.3 was in force. The steward who owned that definition is named. The approval record is traceable. The user’s entitlements at the time of the query are recorded.
The failure taxonomy now has somewhere to land. If the answer was wrong despite correct context, that is a model failure: retrain, fine-tune, or swap the model. If the answer was technically correct against a stale or incorrect glossary term, that is a context failure: the governance artefact was the problem, not the model. If the answer was contextually and semantically correct but violated a policy the system had no record of, that is a policy gap: the wiring between the policy registry and the evaluation graph was incomplete. And if the answer was correct for one user’s entitlements but wrong for another’s, that is a user context failure: the system did not account for who was asking.
What Each Team Does Next
The governance steward should identify the AI use case in your organisation with the highest regulatory exposure. Find the catalog entries for the data it touches. Check whether those entries have versioned definitions with effective date ranges, named stewards, and documented lineage to source systems. If they do not, and in most organisations they will not, at least not completely, that is where context drift enters. Close that gap before wiring anything to evals. Propagating incomplete governance into evaluation infrastructure makes the problem harder to see, not easier.
The LLMOps engineer should instrument a ContextSnapshot capture as a pre-run hook on your highest-stakes eval suite. It does not need to be a full graph. A JSON record containing the glossary term versions, policy versions, and user entitlements relevant to the task domain, written to a table with the run_id as the join key, is enough to start. The schema can be formalised incrementally. The habit of capturing context at run time cannot be retrofitted; it must be established from the first instrumented run.
The risk and compliance professional should stop accepting evaluation reports that contain no context provenance. A report that states “the model scored 0.87 on groundedness” without specifying which version of which definitions that score was computed against is not an auditable document. Ask for the snapshot. The inability to produce one is itself a material finding.
Where This Breaks Down
The catalog maturity problem, noted earlier, is worth restating in practical terms for anyone beginning this work. Partial coverage, inconsistently maintained glossary entries, lineage that stops at the ingestion layer: pretending otherwise is the surest way to discredit the argument with practitioners who live in that reality.
Pick the first domain using three criteria applied together, not sequentially: regulatory exposure is highest, catalog maturity is most advanced for that domain, and evaluation tooling is already instrumented. All three must hold. One out of three produces a prototype that never leaves the proof-of-concept stage. Two out of three produces an integration that exposes gaps faster than teams can fill them. Three out of three produces evidence.
Then follow these three moves. Attach one evaluation run to one existing governance artefact: a single glossary term with a real version history is sufficient. Define the minimal evaluation graph schema for that run using the six node types above. Treat the first reproducible result, the first time you can replay a run against an archived snapshot and confirm the score is stable, as proof of concept. Not proof of scale. Proof of the principle.
Some failure modes remain outside this framework. Helpfulness is still subjective. User satisfaction cannot be derived from a policy version. The evaluation graph resolves the reproducibility and auditability problem. It does not resolve the harder problem of what good actually means to the person asking the question. That requires a different kind of work, and conflating the two is how the scope of this effort becomes impossible to deliver.
Conclusion
The infrastructure to solve this problem already exists in most large organisations. Governance teams have spent years building lineage graphs, business glossaries, data catalogs, and policy registries. AI teams have spent years instrumenting evaluation pipelines that log every run. Both layers are present. Neither is connected to the other.
The evaluation graph is the connection. It is not a new platform, a replacement for existing tooling, or a transformation programme. It is a context provenance layer: a typed, versioned record that answers the question every compliance team will eventually ask: what was the system operating against when it produced this result, and can you prove it?
Context drift is not a future risk. It is occurring in every production AI system running inside a large organisation today. Definitions are changing. Policies are being updated. Data sources are being recertified or deprecated. The evaluation pipeline does not know. The gap between what the system is being measured against and what it is actually operating against widens with every quarter that passes without a context snapshot in the eval record.
The organisations that build this before an incident will explain their architecture. The ones that build it after will explain their incident first.
If this argument resonates with your own experience, if you have sat in a room where a compliance team could not sign off on an evaluation result and nobody could explain why, I’d like to hear about it. The evaluation graph is a framework in progress, not a finished standard. The patterns that emerge from regulated industries will shape how this matures.
Author Connect

Connect with me on LinkedIn or find the extended discussion in the AgentBuild newsletter, where I write about production AI architecture for enterprise practitioners.
*Note: Views expressed are those of the contributor. All submissions are vetted for quality and relevance. Context and Chaos is information-first: no promotions, paid or otherwise.
The Cats of Context & Chaos

That’s all for this edition. Stay curious, keep exploring, and see you all in the next one!
About Context & Chaos
Context & Chaos isn’t just a newsletter. It’s shared community space where practitioners, builders, and thinkers come together to share stories, lessons, and ideas about what truly matters in the world of data and AI: context engineering, governance, architecture, discovery, and the human side of doing meaningful work.
Our goal is simple, to create a space that cuts through the noise and celebrates the people behind the amazing things that are happening in the data & AI domain.
Whether you’re solving messy problems, experimenting with AI, or figuring out how to make data more human, Context & Chaos is your place to learn, reflect, and connect.
Got something on your mind? We’d love to hear from you. Hit Reply!
 | A guest post by
|
This hits the exact structural nerve of why enterprise AI is failing in production. You are defining the architectural solution to what is, at its core, a 50-year-old error in probability theory.
When you argue that AI needs a Context Graph as an evaluation infrastructure, you are effectively demanding a mechanism to enforce the Observational Sufficiency Principle (OSP). (For more detail please see: https://trissimondsen.wordpress.com/2026/05/19/the-observational-sufficiency-principle-osp-canonical-specification-and-formal-proof/)
Right now, developers build models as Fully Specified Stochastic Processes (FSSPs). In the training environment, every variable is known, and the model flawlessly computes the posterior. But when that model hits production - a messy enterprise data environment filled with ambiguity - it encounters M_live, a strictly underspecified reality.
Because these agents lack the governance of a Context Graph, they cannot evaluate their own epistemic boundaries. Their observable σ-algebra (ℱ) is incomplete. However, because an AI is a prediction engine, it refuses to halt. Instead, it implicitly injects spurious parameters (it hallucinates the missing context) to force a resolution. The system degrades into a Spurious Stochastic Process (SSP).
This is the exact same structural error analysts make in the Monty Hall Problem when they inject the unobserved (q = 0.5) host assumption just to force the math to yield (2/3).
Your thesis proves that a Context Graph isn't just a data engineering utility - it is the formal mathematical boundary that prevents an AI from inventing reality. It binds the agent strictly to what is observationally sufficient. If the graph shows the context is underspecified, the system is mathematically required to halt and query the human, rather than confidently executing a hallucinated assumption.
Brilliant piece. It provides the exact infrastructure needed to hardcode OSP into enterprise AI.
The "context drift has no standard detection mechanism" framing is what makes this piece important. Model drift has tooling, benchmarks, monitoring. Context drift — where the governed meaning of a correct answer changes without the evaluation infrastructure knowing — is invisible by default. That asymmetry is exactly how systems pass eval and fail production simultaneously.
The evaluation graph as an audit trail tied to versioned context snapshots is the right architecture. The reason it hasn't been built is also correctly diagnosed: governance teams and AI teams measure success on completely different axes and have no shared incentive to converge until something breaks in compliance.
I write about production AI systems and distributed backends — retrieval and evaluation infrastructure is exactly the layer I think about. Worth a subscribe here too.